

◆ドーパミン不足がアルツハイマー病の記憶障害を引き起こすことを発見
◆“1時間後の脳”に現れる人間のストレス適応メカニズム
◆価値情報から行動選択への橋渡しをする腹側線条体の仕組み
◆繰り返した体験を記憶として定着させるメカニズムの発見
◆うまくいっていた行動が通用しないとき:大脳基底核回路はいかにしてより望ましい結果を探し続けるか
◆シナプスの個性を1細胞丸ごとで可視化する新技術を開発
◆頭蓋骨透明化技術「SeeThrough(シースルー)」の開発
◆喉において気道防御反射を担う感覚細胞の発見
◆『見る』ために重要な抑制性神経伝達物質GABAの網膜での機能的多様性を解明
◆ポジティブ情動が記憶を強化する神経メカニズムの解明
◆脊髄損傷後の運動麻痺改善に重要な脳内経路の解明 ―神経リハビリテーション療法への応用に期待―
◆視覚が生じる前の網膜活動が緻密な神経回路網を設計する
◆中年太りを引き起こす神経細胞のかたちの変化
◆Ca2+やcAMP を感知する蛍光タンパク質を開発
◆抗うつ作用に重要な脳領域を発見
◆報酬とリスクの意思決定バランスを光で調節 ―精神神経疾患の病態解明に期待―
◆神経回路リモデリングにおいて特定のニューロン構造を選択的に除去するメカニズム
◆糖の摂食により痛覚応答が抑えられる仕組みを解明 ――個体の栄養状態に応じた末梢痛覚のチューニング――
◆リズム知覚における小脳と大脳基底核の機能の違い
◆眠りの量と眠気を制御するリン酸化経路
◆うつ症状を生じる脳内メカニズムとその制御法
◆闇夜に揺れる柳から、なぜ逃げ出してしまうのか? ― 恐怖と θ 活動の話
◆統合失調症を引き起こす巨大なシナプス
◆同じ失敗を繰り返さないために必要な脳内メカニズムの解明
◆大人の脳で作られた神経細胞のシナプスの数を調節する仕組みを発見
◆マウス脳における複雑な視覚神経ネットワークの形成過程を解明
◆挑発を受けると攻撃的になる脳内の仕組み
◆体の「痛い」を脳から治す ―痛みに関わる神経回路を標的とした疼痛の新たな治療戦略―
◆体温の中枢調節の基本原理
◆言葉が示す内容と記された色の矛盾を乗り越えるための脳のしくみ
◆ラットも音楽のビートに合わせて身体を動かすことを発見
◆運動指令信号と感覚信号が統合されて運動が作り出される過程を発見
◆シナプス貪食を介した神経回路の最適化
◆シナプスの個性を決める分子群の微細な集積構造 -脳標本とともに『膨らむ』神経科学研究の夢-
◆記憶をアップデートする仕組みを解明
◆シナプス集積によって情報統合のダイナミックレンジを広げる仕組み
◆オスマウスのフェロモンがオス同士の争いを引き起こす神経メカニズム
◆父親の子育てを支える神経回路の変化
◆リズムに合わせて動くための小脳による予測的な運動制御メカニズム
◆レム睡眠の開始機構を解明 ~睡眠周期の生成に関するドーパミンと扁桃体の新たな役割の発見~
◆記憶の獲得によって脳領域横断的に情報を統合する ネットワークが形成される
◆発症1週間後の脳梗塞マウスで治療効果を発揮する蛋白質徐放性ゲル化ペプチドの開発
◆温度を感じる分子がストレス応答に関わるしくみ
◆光で記憶を消去する―記憶に睡眠が必要な理由を解明―
◆繰り返し見た画像であれば見にくくなっても知覚できる脳の仕組み
◆水と油の関係でわかった記憶形成の分子機構
◆女性ホルモンが「かゆみ」の感受性を変えるしくみ
◆脳梗塞による細胞死を抑える分子メカニズム
◆X線を使った脳神経操作法の開発
◆「視覚的な動き」はまず網膜の神経軸索終末で検出される
◆視覚野は外界情報だけでなく、動物の内的な状態も表現する
◆脳はハブ細胞が存在するエコなシステムであった
◆「用意,ドン」フライングせずに行動を準備する脳内メカニズム
◆相互に抑制する扁桃体抑制性神経核による恐怖状態の協調制御
◆脳が完成するまでに「生き残る」回路と「刈り込まれる」回路との違いを解明
◆未来の行動に先立って成功確率を予測する仕組みを解明
◆空間認識を支える脳情報の流れを解明
◆生まれたての神経細胞が旅立つ最初期ステップを解明~脳室面に付着した神経細胞の足をDSCAMタンパク質が切り剥がす~
◆状況に応じて物の価値判断を変化させる脳の仕組みを解明
◆神経活動を操作する新技術『化学遺伝学』に、飛躍的に性能が向上した薬剤が登場
◆脳内のグリア細胞―神経細胞間コミュニケーションを解き明かす 空間的分子探索技術の創出
◆母性ホルモン・オキシトシンがオスの性機能を促進させる新たな局所神経機構を解明
◆途切れた神経回路を再びつなぐ人工シナプスコネクターを開発 ~シナプス異常による精神・神経疾患の治療に新しい道~
◆冬眠様状態を誘導する神経経路の発見
◆謎の脳領域「前障」は睡眠中の脳活動を制御する
◆塩のおいしさを生み出す細胞とその仕組み
◆心と身体をつなぐ脳の神経回路メカニズム
◆適切な意思決定を可能にする神経回路を同定
◆レム睡眠中の記憶忘却を誘導する視床下部MCH神経
◆視床下部神経回路の周期的なリモデリングによる雌性行動の制御
◆世界最高性能 Ca2+センサー 『XCaMP』開発による脳情報動態の精密解読
◆脳内神経回路再編をもたらすシナプス形成因子の新しい分泌様式を解明 -神経活動に応じたシナプスの「スクラップ&ビルド」-
◆神経活動の時間的なパターンに基づいた神経ネットワーク形成
◆「根気」は海馬とセロトニンが制御する
◆意思決定の個体差を生む脳内機構 -外的撹乱に対する神経活動の応答性の違いが行動選択の個性を決める-
◆“1時間後の脳”に現れる人間のストレス適応メカニズム
◆価値情報から行動選択への橋渡しをする腹側線条体の仕組み
◆繰り返した体験を記憶として定着させるメカニズムの発見
◆うまくいっていた行動が通用しないとき:大脳基底核回路はいかにしてより望ましい結果を探し続けるか
◆シナプスの個性を1細胞丸ごとで可視化する新技術を開発
◆頭蓋骨透明化技術「SeeThrough(シースルー)」の開発
◆喉において気道防御反射を担う感覚細胞の発見
◆『見る』ために重要な抑制性神経伝達物質GABAの網膜での機能的多様性を解明
◆ポジティブ情動が記憶を強化する神経メカニズムの解明
◆脊髄損傷後の運動麻痺改善に重要な脳内経路の解明 ―神経リハビリテーション療法への応用に期待―
◆視覚が生じる前の網膜活動が緻密な神経回路網を設計する
◆中年太りを引き起こす神経細胞のかたちの変化
◆Ca2+やcAMP を感知する蛍光タンパク質を開発
◆抗うつ作用に重要な脳領域を発見
◆報酬とリスクの意思決定バランスを光で調節 ―精神神経疾患の病態解明に期待―
◆神経回路リモデリングにおいて特定のニューロン構造を選択的に除去するメカニズム
◆糖の摂食により痛覚応答が抑えられる仕組みを解明 ――個体の栄養状態に応じた末梢痛覚のチューニング――
◆リズム知覚における小脳と大脳基底核の機能の違い
◆眠りの量と眠気を制御するリン酸化経路
◆うつ症状を生じる脳内メカニズムとその制御法
◆闇夜に揺れる柳から、なぜ逃げ出してしまうのか? ― 恐怖と θ 活動の話
◆統合失調症を引き起こす巨大なシナプス
◆同じ失敗を繰り返さないために必要な脳内メカニズムの解明
◆大人の脳で作られた神経細胞のシナプスの数を調節する仕組みを発見
◆マウス脳における複雑な視覚神経ネットワークの形成過程を解明
◆挑発を受けると攻撃的になる脳内の仕組み
◆体の「痛い」を脳から治す ―痛みに関わる神経回路を標的とした疼痛の新たな治療戦略―
◆体温の中枢調節の基本原理
◆言葉が示す内容と記された色の矛盾を乗り越えるための脳のしくみ
◆ラットも音楽のビートに合わせて身体を動かすことを発見
◆運動指令信号と感覚信号が統合されて運動が作り出される過程を発見
◆シナプス貪食を介した神経回路の最適化
◆シナプスの個性を決める分子群の微細な集積構造 -脳標本とともに『膨らむ』神経科学研究の夢-
◆記憶をアップデートする仕組みを解明
◆シナプス集積によって情報統合のダイナミックレンジを広げる仕組み
◆オスマウスのフェロモンがオス同士の争いを引き起こす神経メカニズム
◆父親の子育てを支える神経回路の変化
◆リズムに合わせて動くための小脳による予測的な運動制御メカニズム
◆レム睡眠の開始機構を解明 ~睡眠周期の生成に関するドーパミンと扁桃体の新たな役割の発見~
◆記憶の獲得によって脳領域横断的に情報を統合する ネットワークが形成される
◆発症1週間後の脳梗塞マウスで治療効果を発揮する蛋白質徐放性ゲル化ペプチドの開発
◆温度を感じる分子がストレス応答に関わるしくみ
◆光で記憶を消去する―記憶に睡眠が必要な理由を解明―
◆繰り返し見た画像であれば見にくくなっても知覚できる脳の仕組み
◆水と油の関係でわかった記憶形成の分子機構
◆女性ホルモンが「かゆみ」の感受性を変えるしくみ
◆脳梗塞による細胞死を抑える分子メカニズム
◆X線を使った脳神経操作法の開発
◆「視覚的な動き」はまず網膜の神経軸索終末で検出される
◆視覚野は外界情報だけでなく、動物の内的な状態も表現する
◆脳はハブ細胞が存在するエコなシステムであった
◆「用意,ドン」フライングせずに行動を準備する脳内メカニズム
◆相互に抑制する扁桃体抑制性神経核による恐怖状態の協調制御
◆脳が完成するまでに「生き残る」回路と「刈り込まれる」回路との違いを解明
◆未来の行動に先立って成功確率を予測する仕組みを解明
◆空間認識を支える脳情報の流れを解明
◆生まれたての神経細胞が旅立つ最初期ステップを解明~脳室面に付着した神経細胞の足をDSCAMタンパク質が切り剥がす~
◆状況に応じて物の価値判断を変化させる脳の仕組みを解明
◆神経活動を操作する新技術『化学遺伝学』に、飛躍的に性能が向上した薬剤が登場
◆脳内のグリア細胞―神経細胞間コミュニケーションを解き明かす 空間的分子探索技術の創出
◆母性ホルモン・オキシトシンがオスの性機能を促進させる新たな局所神経機構を解明
◆途切れた神経回路を再びつなぐ人工シナプスコネクターを開発 ~シナプス異常による精神・神経疾患の治療に新しい道~
◆冬眠様状態を誘導する神経経路の発見
◆謎の脳領域「前障」は睡眠中の脳活動を制御する
◆塩のおいしさを生み出す細胞とその仕組み
◆心と身体をつなぐ脳の神経回路メカニズム
◆適切な意思決定を可能にする神経回路を同定
◆レム睡眠中の記憶忘却を誘導する視床下部MCH神経
◆視床下部神経回路の周期的なリモデリングによる雌性行動の制御
◆世界最高性能 Ca2+センサー 『XCaMP』開発による脳情報動態の精密解読
◆脳内神経回路再編をもたらすシナプス形成因子の新しい分泌様式を解明 -神経活動に応じたシナプスの「スクラップ&ビルド」-
◆神経活動の時間的なパターンに基づいた神経ネットワーク形成
◆「根気」は海馬とセロトニンが制御する
◆意思決定の個体差を生む脳内機構 -外的撹乱に対する神経活動の応答性の違いが行動選択の個性を決める-

うまくいっていた行動が通用しないとき:大脳基底核回路はいかにしてより望ましい結果を探し続けるか
東京科学大学 大学院医歯学総合研究科 細胞生理学分野
助教
Alain Rios (アライン リオス)
助教
Alain Rios (アライン リオス)
日常生活では、うまくいっていた行動が通用しなくなっても、同じやり方を続けてしまうことがあります。本研究では、望ましいはずの行動で結果が出ないとき、大脳基底核の間接路が代替案を模索し続ける役割を果たすことで柔軟な行動適応を可能にすることを実証しました。
日常生活では、通勤ルートや問題の解き方など「うまくいきそうな」行動を何度も繰り返しています。こうした行動は効率的ですが、環境が変わって通用しなくなっても同じ行動を続けてしまいがちです。では脳はどのようにして「このやり方はもう通用しない」と気づき、別の選択肢を試させるのでしょうか。
大脳基底核は試行錯誤による学習を支える脳回路を構成します。特に大脳基底核の線条体から出力する「直接路」は望ましい果をもたらした行動を強化し、「間接路」は望ましくない結果につながった行動を抑えることで報酬を最大化し、行動を最適化すると考えられてきました。
今回の研究では、間接路がさらに能動的に別の選択肢を探る働きをしていることを示しました。一見「望ましい」行動方策でも、その信頼度が下がってきたときにそれを見極め、別の選択肢を探り続けるように脳を助けているのです。
具体的には、ラットに前脚でレバーを押すか引くかを選んで報酬の水滴を得る課題を学習させました。一方の行動では高い確率で、他方では低い確率で報酬が得られ、ときどき予告なしにこの確率を入れ替えました。効率よく水を得続けるには、それまでの「望ましい」行動がもはや望ましくないことに気づき、他方へ切り替える必要があります。
上記の行動課題を遂行中のラットから大脳基底核の直接路と間接路のニューロンを区別して発火活動を記録しました。その結果、報酬確率が高いはずの行動で得られる報酬頻度が減った場合、報酬確率が低い行動をあえて試みて報酬が得られなかったとき、間接路ニューロンは次の選択まで活動を続けることがわかりました。驚いたことに、この活動が強いほど、ラットはすぐには元の報酬確率が高いはずの行動に戻らず、しばらく元の報酬確率が低いはずの行動(代替行動)を試し続けました。
さらに、この間接路ニューロンの、報酬非獲得試行後に音刺激(結果音)から約0.5秒以降に立ち上がり、次の試行まで続く遅い持続的な活動をオプトジェネティクスにより光照射で人為的に強めると、ラットは報酬が得られなかった後でも代替行動を試す頻度が増加しました。一方、従来の報告通り、音刺激直後0〜0.5秒に一過性に生じる早い時期の活動を強めると、次に代替行動を試す頻度が減少しました。つまり、同じ間接路が、結果直後の早い時期には報酬最大化方策を維持するモードとして、結果後半の遅い時期には方策が通用しないときに新しい選択肢を探るモードとして働く、二つの制御様式を担っていることを示すことができました。
この成果から、大脳基底核は従来の報酬最大化機能に加えて、環境の変化に応じて行動の信頼性を評価し、行動を柔軟に、効率的に切り替える機能を担うことが示されました。本研究成果は行動の切り替えが難しい病気の理解にも役立つと期待されます。
<論文情報>
タイトル:Dorsomedial striatum monitors unreliability of current action policy and probes alternative one via the indirect pathway
著者:Alain Rios, Satoshi Nonomura, Yutaka Sakai, Kazuto Kobayashi, Shigeki Kato, Masahiko Takada, Yoshikazu Isomura, Minoru Kimura,
著者:Alain Rios, Satoshi Nonomura, Yutaka Sakai, Kazuto Kobayashi, Shigeki Kato, Masahiko Takada, Yoshikazu Isomura, Minoru Kimura,
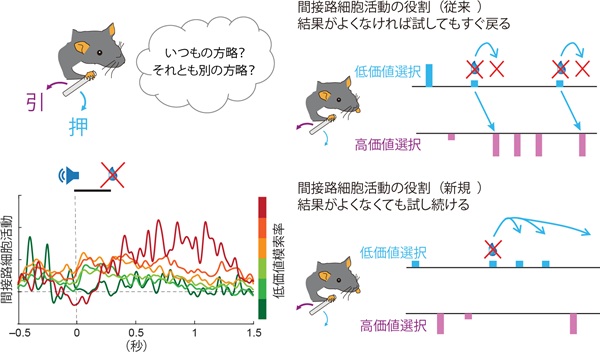
<図の説明>
この課題では、ラットが前脚でレバーを「押す」か「引く」かを選び、どちらの行動で報酬が得られるかを学習します(左上)。左下のグラフは、報酬が得られなかった試行のあとに、大脳基底核の背内側線条体の間接路ニューロンがどのように活動するかを示しています。線の色は「低価値探索率」(右のカラーバー)を表しており、遅い応答が強い(赤・オレンジ)ほどラットは低価値の代替行動を試し続け、弱い(緑)ほどすぐにいつもの高価値行動に戻ります。従来は、これらのニューロンは「報酬につながらなかった行動を止める」ことで、高価値の行動に戻す役割が中心だと考えられてきました(右上)。本研究の結果はそれに加えて、いつもの行動がうまくいかなくなったときに、報酬のあともしばらく続く活動が代替行動の試行を後押しし、より信頼できる新しい方略が見つかるまで探索を続けさせる役割を持つことを示しています(右下)。
<研究者の声>
本研究を通じて、大脳基底核の働きには教科書的な説明だけでは捉えきれない側面があることを改めて実感しました。数年にわたり神経活動を記録し、行動データを丁寧に見直す中で、最も重要なシグナルは、動物が「いつもの方略」でうまくいかなくなった場面で現れることが分かってきました。安定して訓練できるほどシンプルでありながら、時間とともに行動方略の変化を引き出せる課題設計が大きなチャレンジの一つでした。また、多ニューロン同時記録、オプトジェネティクス、計算モデル解析といった異なる手法を一つの枠組みとして統合するために、共同研究者との議論と再解析を何度も重ねる必要がありました。査読プロセスでは、とくに回路ダイナミクスと行動の関係を分かりやすく示す点について、多くの有益なフィードバックをいただき、解釈と説明をより洗練させることができました。
<略歴>
アライン リオスAlain Rios, MD, PhD
東京科学大学 大学院医歯学総合研究科 細胞生理学分野・助教。大脳基底核回路がどのように柔軟な意思決定を支えているかに関心を持ち、ラットの意思決定課題中の多ニューロン同時記録、オプトジェネティクス、ファイバーフォトメトリーなどを用いて研究している。現在は、報酬処理における海馬鋭波リップルの役割についても探索している。
東京科学大学 大学院医歯学総合研究科 細胞生理学分野・助教。大脳基底核回路がどのように柔軟な意思決定を支えているかに関心を持ち、ラットの意思決定課題中の多ニューロン同時記録、オプトジェネティクス、ファイバーフォトメトリーなどを用いて研究している。現在は、報酬処理における海馬鋭波リップルの役割についても探索している。



HOME | 一般社団法人 日本神経科学学会
- 学会機関紙
- Neuroscience Research
- Articles in Press
- Latest Issue
- Back Issues
- Submit Your Paper
- About the Journal
- 電子版の購読について
(会員の方へ) - お知らせ
- 公募情報 助成・受賞
- 研究員・教職員募集
- 大学院生募集・説明会
- 研究助成・渡航助成募集
- 受賞候補者募集
- キャリアパスに応じた賞・助成
- 海外の学会への旅費支援
- 学会推薦による賞・助成
- 成茂神経科学研究助成基金
- イベント・研究会情報
- イベント・研究会
- 一般の方向けイベント
- 会員ページ
- Neuroscience Research (NSR) 電子版閲覧
- 抄録検索システム [IDパスワードが必要]
- 会員ログイン
- 過去の神経科学ニュース